Tipos de bases de datos no relacionales
Este post, tipos de bases de datos no relacionales, es continuación de un primero, donde hablé de Azure y bases de datos no relacionales, y de un segundo donde hablé de tipos de datos no relacionales.
Es esos posts anteriores comenté la diferencia entre datos estructurados, semiestructurados, o no estructurados; el resumen es que los “datos no relacionales” son todo aquello que no esté estructurado como un conjunto de tablas. Y habiendo diferentes tipos de datos no estructurados la consecuencia es que también hay diferentes sistemas de bases de datos no relacionales, pensados para solventar las diferentes casuísticas.

Antes de entrar a describir estos sistemas hay que aclarar lo que término NoSQL significa, o puede significar: tanto “no relacional”, como “no solo relacional”. Puesto que algunas bases de datos no relacionales sí admiten una versión de SQL, pero adaptada para documentos y no las habituales tablas, como en el caso de Azure Cosmos DB.
Base de datos pares clave-valor
Es un tipo sencillo de base de datos NoSQL para insertar y consultar datos. El concepto clave-valor significa que los datos se almacenan como una colección de pares clave-valor; la clave identifica de forma única la colección, y el valor contiene los datos, y se ordenan según la clave.
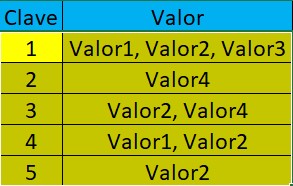
El valor puede ser una imagen, un archivo, un documento, o un conjunto de campos. La base de datos en sí ve todo el valor como un bloque, sin estructura, que la aplicación que utiliza este tipo de base de datos es la que la gestiona. No se puede buscar en los valores sino que se han de utilizar las claves para identificar y recuperar los datos que se requieran. Esto no es significativo puesto que estos sistemas sacan partido de la capacidad de leer y escribir datos rápidamente, no por las opciones de búsqueda. Por tanto, por ejemplo un escenario indicado es cuando se recibe un gran volumen de datos y debe almacenarse rápidamente.
Base de datos de documentos
Este tipo de base de datos, siendo también una base de datos NoSQL, maneja datos semiestructurados. Al revés que la base de datos pares clave-valor, además de también tener un identificador único para cada documento, los campos de los que consta este documento sí son transparentes para el sistema de administración. Pero a diferencia de una base de datos relacional donde los campos de las tablas son siempre los mismos, en las bases de datos documentales cada documento puede tener su propia estructura.

Hay diferentes formatos a utilizar en un “documento”: los más usuales son JSON o XML, aunque también existen otros como YAML o BSON, o incluso como un fichero de texto. Dependiendo de la base de datos documental los identificadores de los documentos se crearán automáticamente o utilizaremos un atributo para usarlo como clave; pero una diferencia clara con las bases de datos pares clave-valor es que como los campos son transparente podemos construir consultas sobre los documentos basándose en ellos, incluso indexando sus valores para permitir una gran velocidad de consulta.
De alguna manera podemos considerar las bases de datos documentales como algo “intermedio” entre las relacionales y las de clave-valor: aunque no ofrecen la consistencia de las primeras ni la velocidad de lectura/escritura de las segundas, ofrecen más velocidad que las primeras y más consistencia que las segundas. Y su flexibilidad a la hora de definir los campos que utilizaremos y la capacidad de consulta son los aspectos más importantes en este tipo de base de datos.
Base de datos de familia de columnas
Estas bases de datos, también llamadas de columnas anchas, con una estructura similar a las bases de datos relacionales, están pensadas para requerir menos consultas a la hora de recuperar datos puesto que guardan todos los datos relacionados en “grupos”, teniendo cada familia de columnas un conjunto de columnas con una relación lógica entre ellas.
Por ejemplo, podríamos tener una tabla de empleados, en la que una familia de columnas llamada “datos personales” estuviera compuesta de diversas columnas con ese tipos de datos (nombre, dirección, etc.); mientras que otra familia de columnas llamada “datos profesionales” se encargara de contemplar ese otro tipo de datos (puesto, salario, etc.).

Ventajas de este tipo de base de datos son: altamente escalable (las familias de columnas incluso se pueden almacenar por separado); los campos también son transparentes y se puede ordenar y manipular los datos desde el sistema de base de datos; también se puede indexar; y permite actualizar valores en una sola columna en vez de reemplazar los datos.
Base de datos de grafos
Un grafo es una colección de elementos (“nodos”), que aportan información, relacionados mediante “aristas”, que son la conexión entre los nodos, y que pueden tener una dirección concreta.

Las bases de datos de grafos representan interacciones complejas entre sus datos, y así realizar consultas eficientes a través de los nodos y aristas analizando sus relaciones. Por ejemplo, un árbol genealógico, o las relaciones de todo el personal de una empresa, o incluso la infraestructura de internet, son grafos; pueden analizarse mediante otros tipos de bases de datos, como las relacionales, pero la optimización de las bases de datos de grafos permiten hacerlo mucho más eficientemente (no harán falta operaciones para combinar datos, ni subconsultas pesadas y repetitivas), especialmente conforme el tamaño de las bases de datos crecen. Además, permiten descubrir conexiones entre los datos difíciles de ver con otros sistemas.
Espero que estos 3 posts hayan os permitan tener una idea más clara sobre bases de datos NoSQL y datos semiestructurados y no estructurados.